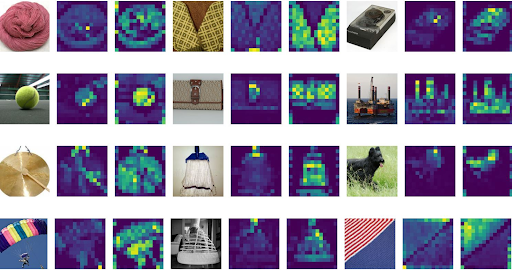
1. Introduction
Ever since the introduction of the self-attention mechanism, Transformers have been the top choice when it comes to Natural Language Processing (NLP) tasks. Self-attention-based models are highly parallelizable and require substantially fewer parameters, making them much more computationally efficient, less prone to overfitting, and easier to fine-tune for domain-specific tasks [1]. Furthermore, the…