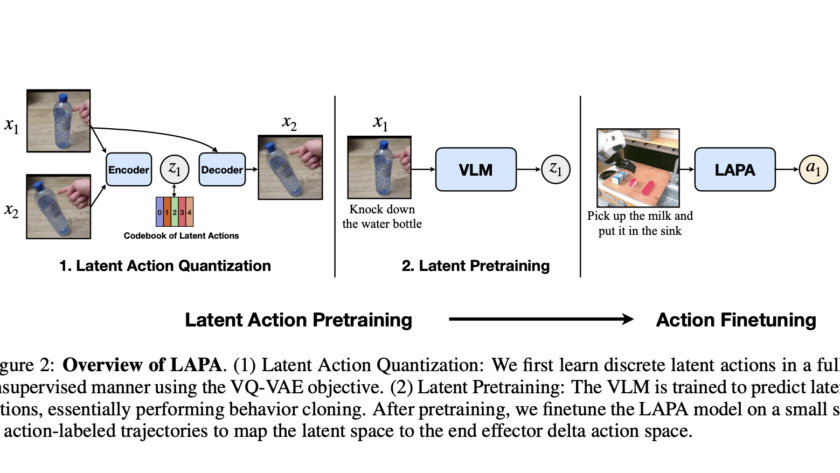
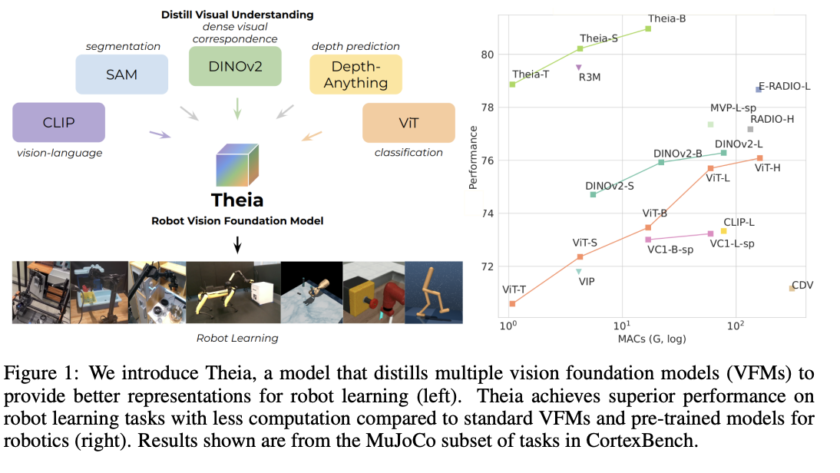
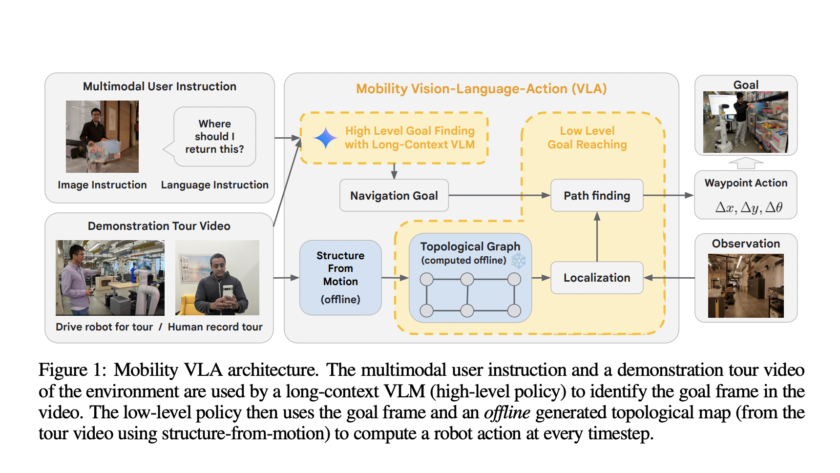
Challenges in Dexterous Hand Manipulation Data Collection
Creating large-scale data for dexterous hand manipulation remains a major challenge in robotics. Although hands offer greater flexibility and richer manipulation potential than simpler tools, such as grippers, their complexity makes them difficult to control effectively. Many in the field have questioned whether dexterous hands are worth the…